In recent years, Energy Trading Risk Management (ETRM) systems have experienced significant technology advances that have brought big gains to allow for portfolio-wide visibility of price, credit, currency, interest rate, and liquidity risks. These improvements, along with, in some cases, efficiencies provided by cloud computing, mean that businesses can achieve a high level of value from their ETRM system.
However, despite these advances, ETRM software owners continue to feel the pain of the ‘testing problem’ when implementing an upgraded software version or making code changes within a current version. Testing is typically confined to a round of regression testing and a round of user acceptance testing (UAT) with system integration testing (SIT) sprinkled between the two testing runs.
Suddenly that total cost of ownership number is getting higher than one might have hoped.
Why Traditional Testing in Allegro Falls Short
While all the best efforts are made to account for every scenario during traditional regression, UAT and SIT testing, resource and time constraints mean that testing is often shoe-horned into narrowly scoped unit tests. This testing style inevitably leaves ETRM owners exposed to the risk that ‘showstopper’ issues are not uncovered until after the new code is moved into production. Indeed, many otherwise successful ETRM projects have ended in frustration, and sometimes failure due to the ‘testing problem.’
Some ETRM owners have tried to develop a more exhaustive set of tests to mitigate the risk of an undiscovered ‘showstopper’ issue. However, manually writing, executing and analyzing a fully exhaustive test set while still using the traditional Regression, UAT, and SIT methodology carries prohibitively high costs and long man hours. These high costs and delays often snowball and can cause a project to blow past its allotted budget and time to completion.
The ’testing problem’ tends to show up in areas of the ETRM with large data sets governed by small teams and where the effects are not manifested until a valuation is run. These tend to be price import errors, currency, interest rate or volatility discrepancies, and even volumetric data integration inaccuracies such as truck ticket imports or Electronic Bulletin Board (EBB) integrations for natural gas.
While frustrating, this is typical of ETRM systems where one or more of the following master data integrity issues are present:
- The team that owns data integrity is not the same as the team that experiences the effects of data errors;
- The team that corrects data errors is not the same as the team that sets master data integrity standards or is not the same as the team that uncovers data errors;
- There is no strong master data governance process that provides exhaustive quality control.
For users of Allegro, the ‘testing problem’ is particularly acute when there are high levels of customization from class events or complex integrations to adjacent software systems. Furthermore, due to Allegro’s client-server software architecture, trying to use a more comprehensive testing framework like Continuous Integration and Continuous Delivery (CI/CD), is ineffective.
Can’t We Automate This?
So, how can Allegro users approach a software upgrade with the confidence that their testing regiment has not left major issues undiscovered? Enter automated testing. The panacea to the ailments of the ‘testing problem’ – right? Well, not quite.
For years now there has been a steady drumbeat of calls for automated testing within the client base of vendor systems. Implicit within these requests is the expectation that automated testing will substantially, if not completely, liberate users from the egregious time and resource commitment of writing and running test cases. For its part, the Allegro vendor answered those calls with an in-house automated testing tool known as ATA. The ATA tool boasts some unique bright spots, such as its ability to mimic the user experience when run through the Horizon UI. However, the major drawback to this tool is the resource capital and time required to configure test scripts using an iterative process.
Removing Iteration from your Automated Tests with Triangle
Is there any hope for running automated tests in Allegro that do not require iteration ad nauseam? At Lucido we have been asking just that question, and we have had our eye on the Triangle Test Automation tool developed by Trinitatum. Triangle Test Automation is a leader of automated testing for the Endur and Findur software systems with its powerful and dynamic test suites. Now, Lucido is partnering with Trinitatum to bring Triangle Test Automation to Allegro.
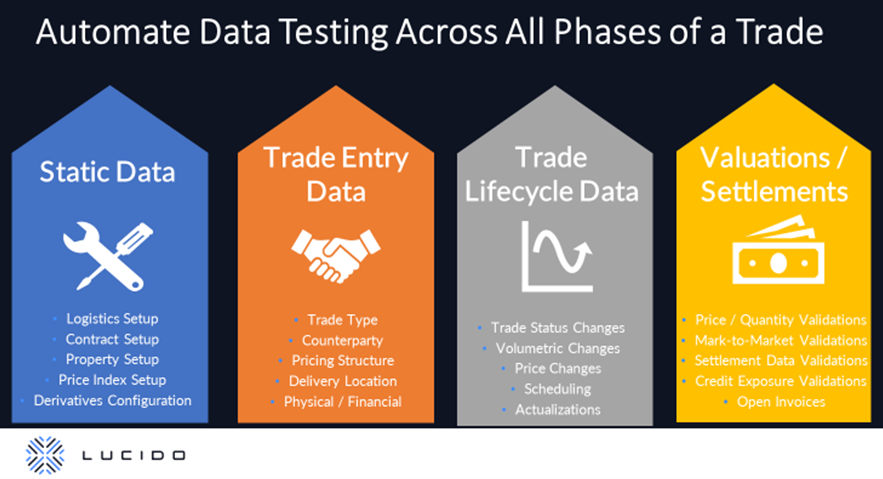
Triangle Test Automation within Allegro allows users to automate data testing simply and quickly across all phases of a deal. This includes static data, trade entry data, volumetric and pricing data, valuations, and settlement data. In short, all data generated over the lifecycle of a trade can be compared and validated, without the need for a skilled tester to write a script. The power of Triangle in Allegro gives testers the ability to easily compare and validate entire data sets between two databases and to quickly pinpoint variances where they exist.
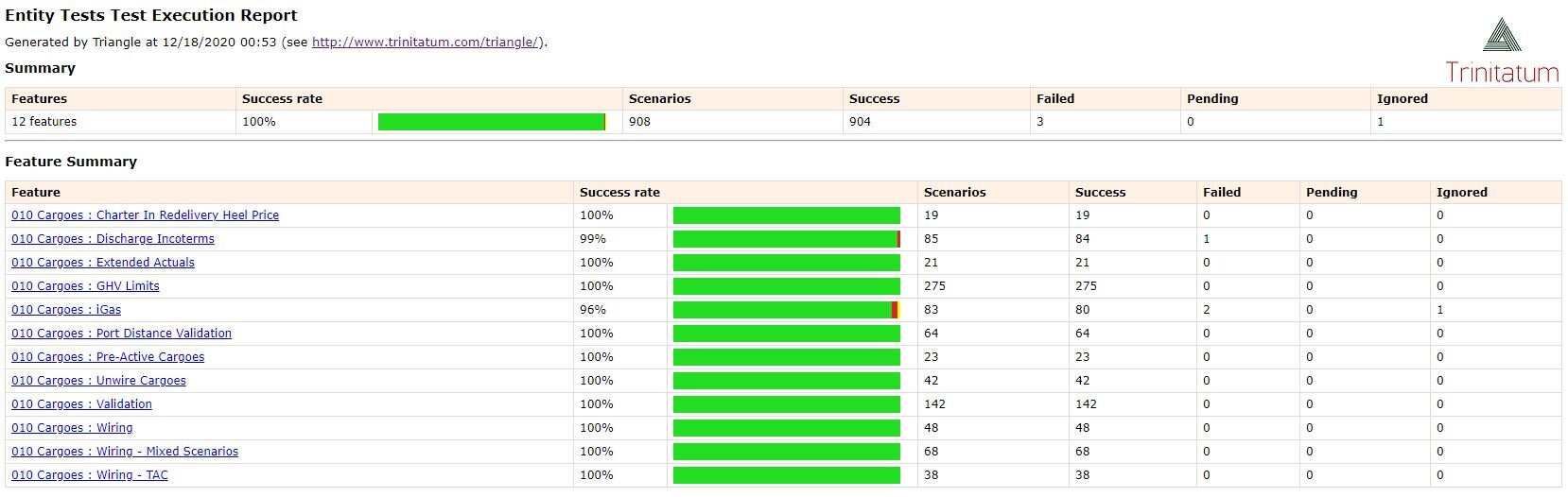
Unlike the native Allegro tool, Triangle test suites come pre-written to compare all applicable, out of the box data tables for a given commodity. This plug-and-play quality means that Allegro users can begin running tests that compare entire data sets almost immediately. Furthermore, Triangle can easily be run through Azure or AWS DevOps and supports both scheduled test runs and ad hoc test execution. Run through DevOps, the report output is clean, and it is simple to understand why a test failed for even the most non-technical users. And for users of Allegro who have extended the data model beyond the Allegro out of the box version, adapting the Triangle tests to include new tables is quick and easy.
Saving Time Through Triangle’s Intelligent Matching
Triangle has powerful capabilities which enable it to match trades from one Allegro environment to another even though the trade IDs are different. Triangle can analyze the underlying qualities of the trade, rather than just the system generated trade number. This ability, known as Intelligent Matching, means that Triangle can quickly find and alert Allegro users of a price, volume, or referential data discrepancy between two trades, saving clients from the painful and time-consuming experience of trying to find these differences manually. Intelligent matching does not just stop at trades, but extends to matching positions, findetail records, invoices and even documents such as PDF trade confirms or PDF invoices.
Another forte of Triangle is that it can easily and quickly handle very large data sets, such as tens of thousands of trades, or hundreds of thousands of prices and volatilities. In today’s changing market where volatilities, interest rates, currencies and prices are extremely dynamic, even a small pricing error or missing a single volatility for a given strike can drive large variances in a valuation. Not to mention the herculean task of tracking a valuation error upstream to the root price error. This is where Triangle’s capabilities allow it to pinpoint a missing or incorrect price, volatility, etc. and alert users easily and quickly before precious resources are wasted on a valuation run where the results will have to be discarded.
After working with both ATA and Triangle Test Automation, the Lucido team is convinced that Triangle has an important and powerful role to play for users of Allegro looking to overcome the ‘testing problem.’ But don’t just take our word for it, let us show you the power of Triangle in Allegro by scheduling a demo today!